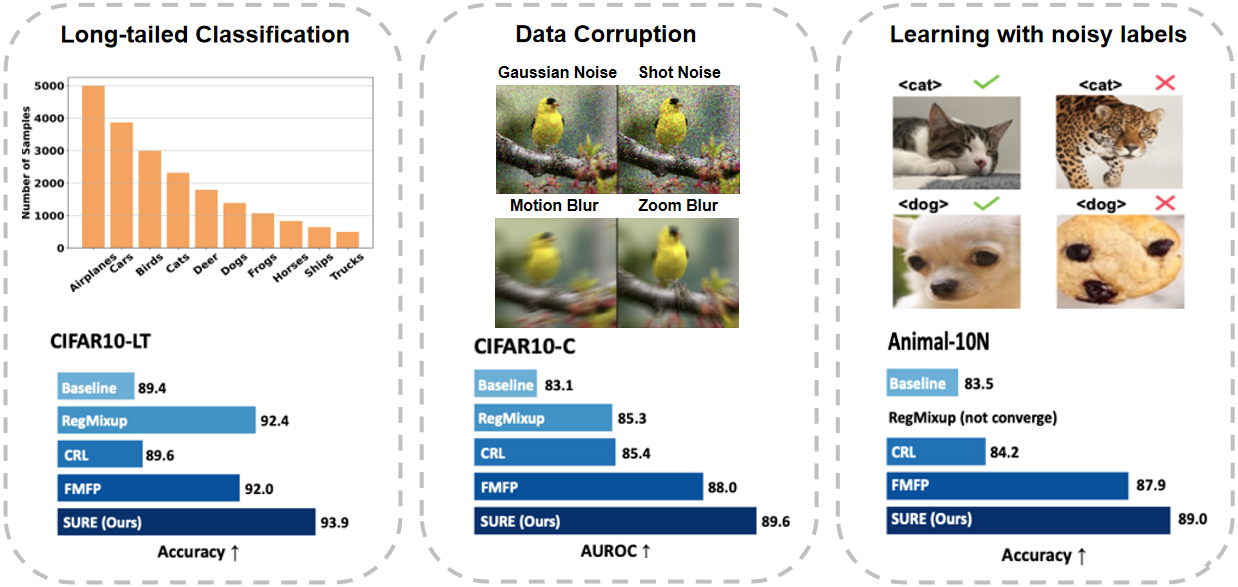
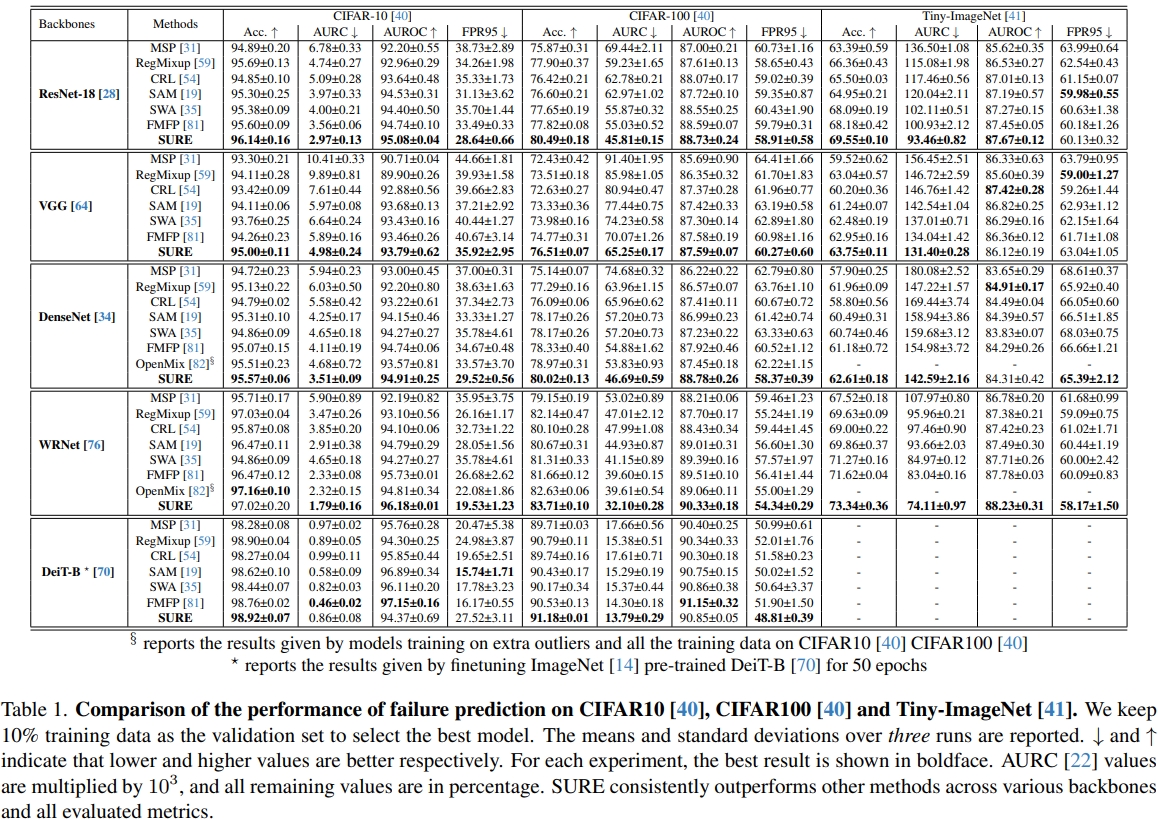
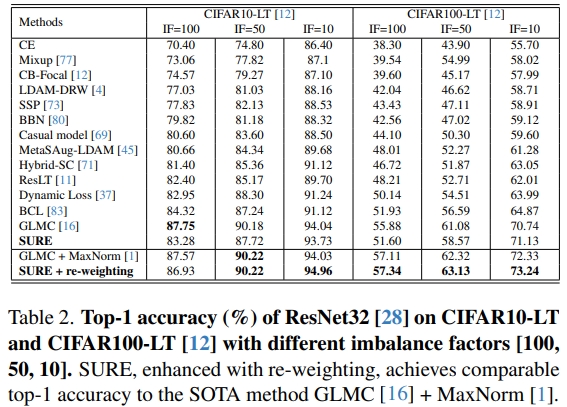
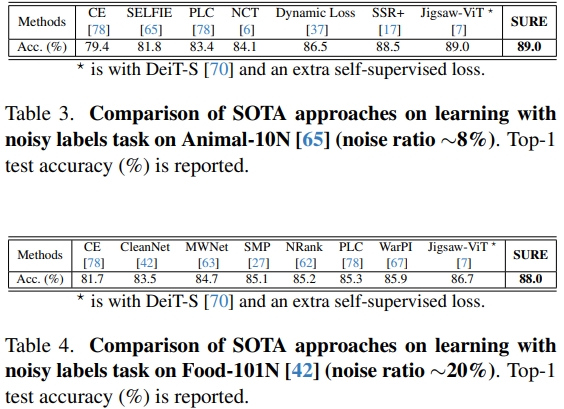
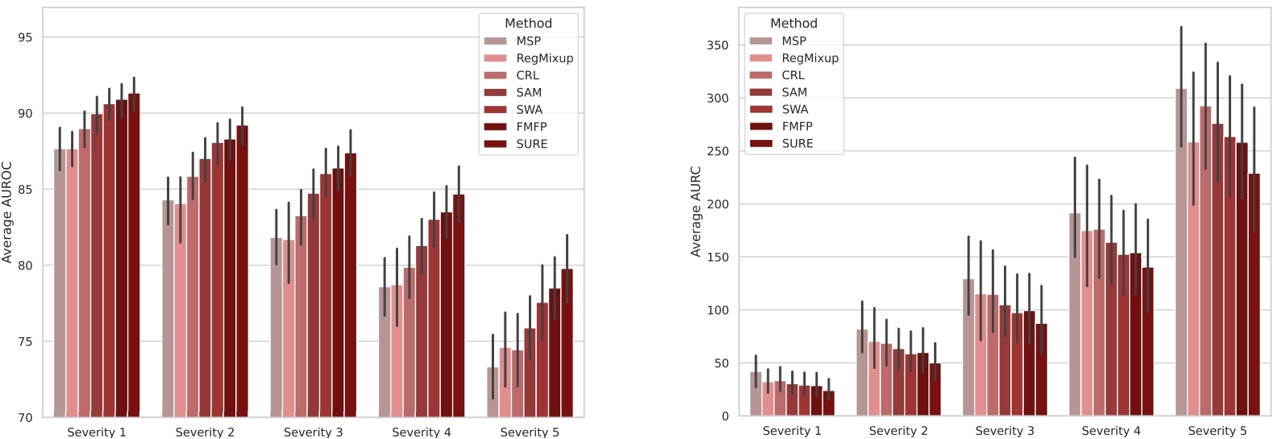
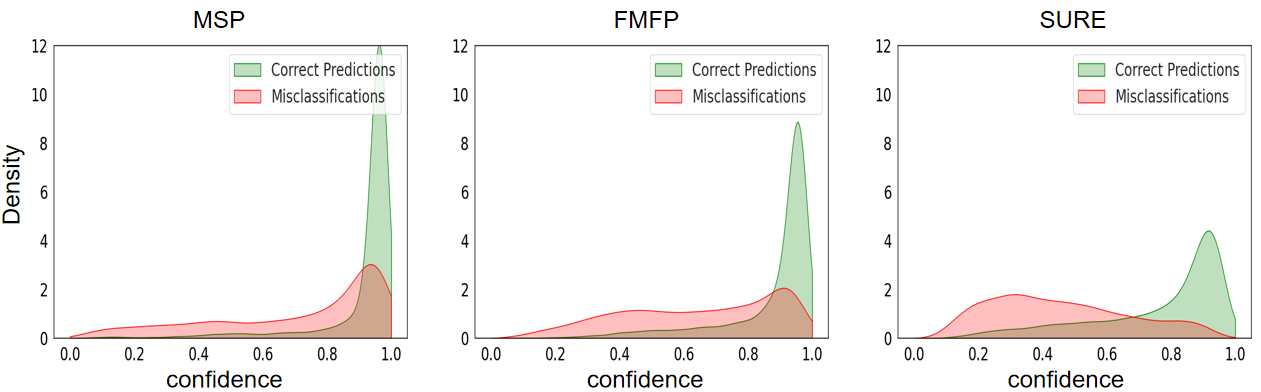
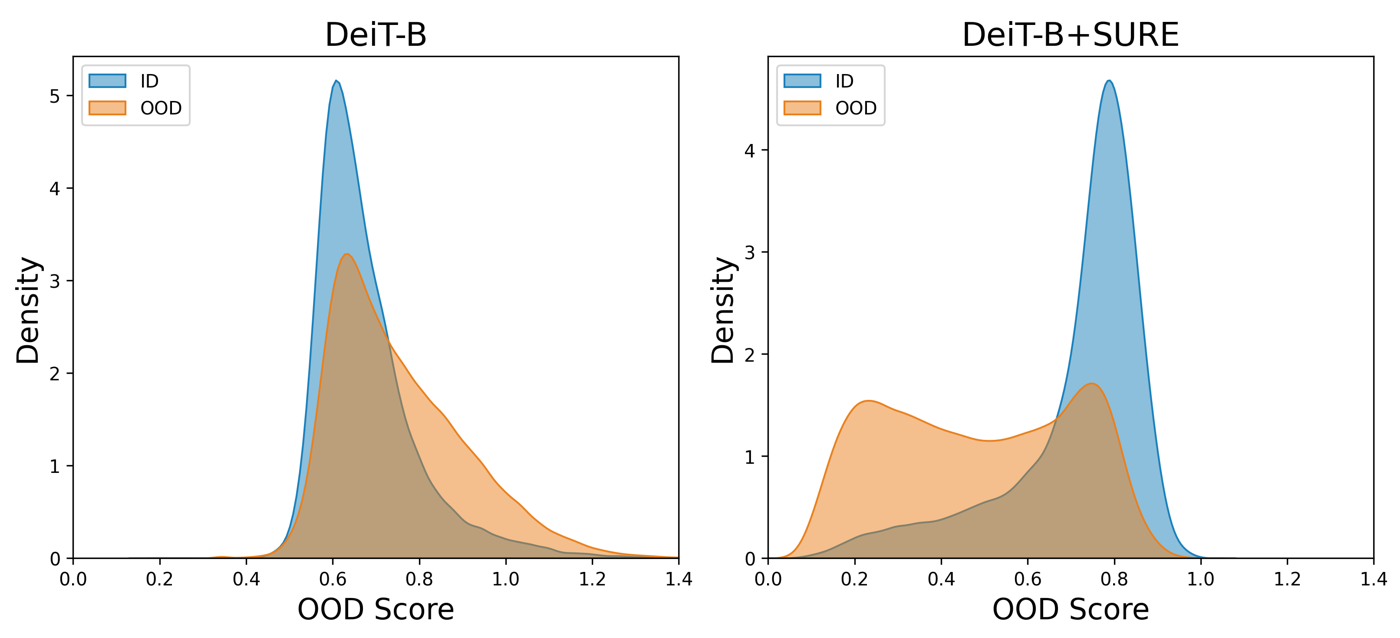
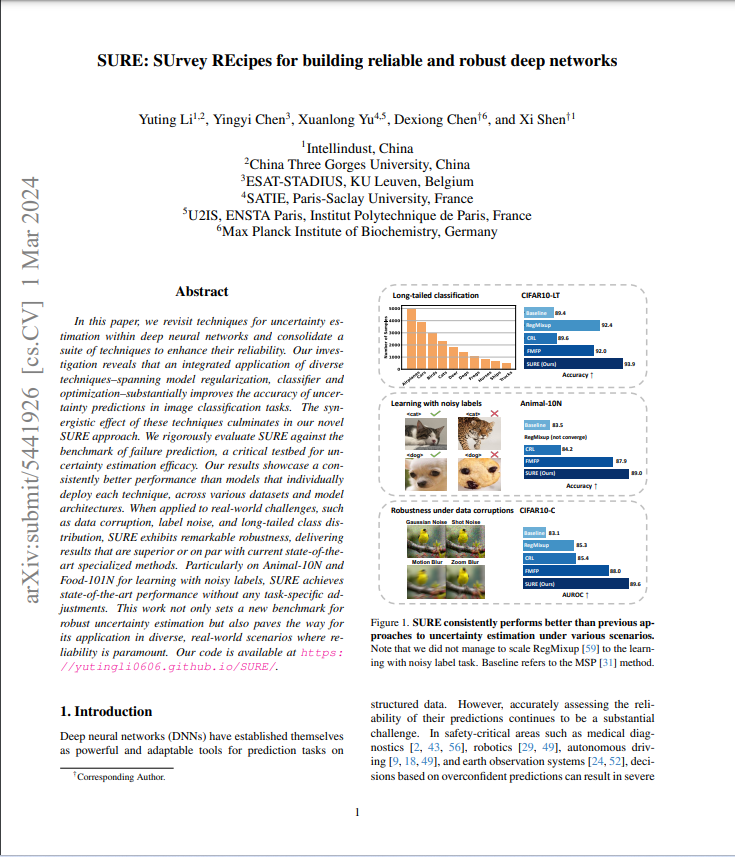
In this paper, we revisit techniques for uncertainty estimation within deep neural networks and consolidate a suite of techniques to enhance their reliability. Our investigation reveals that an integrated application of diverse techniques--spanning model regularization, classifier and optimization--substantially improves the accuracy of uncertainty predictions in image classification tasks. The synergistic effect of these techniques culminates in our novel SURE approach. We rigorously evaluate SURE against the benchmark of failure prediction, a critical testbed for uncertainty estimation efficacy. Our results showcase a consistently better performance than models that individually deploy each technique, across various datasets and model architectures. When applied to real-world challenges, such as data corruption, label noise, and long-tailed class distribution, SURE exhibits remarkable robustness, delivering results that are superior or on par with current state-of-the-art specialized methods. Particularly on Animal-10N and Food-101N for learning with noisy labels, SURE achieves state-of-the-art performance without any task-specific adjustments. This work not only sets a new benchmark for robust uncertainty estimation but also paves the way for its application in diverse, real-world scenarios where reliability is paramount.
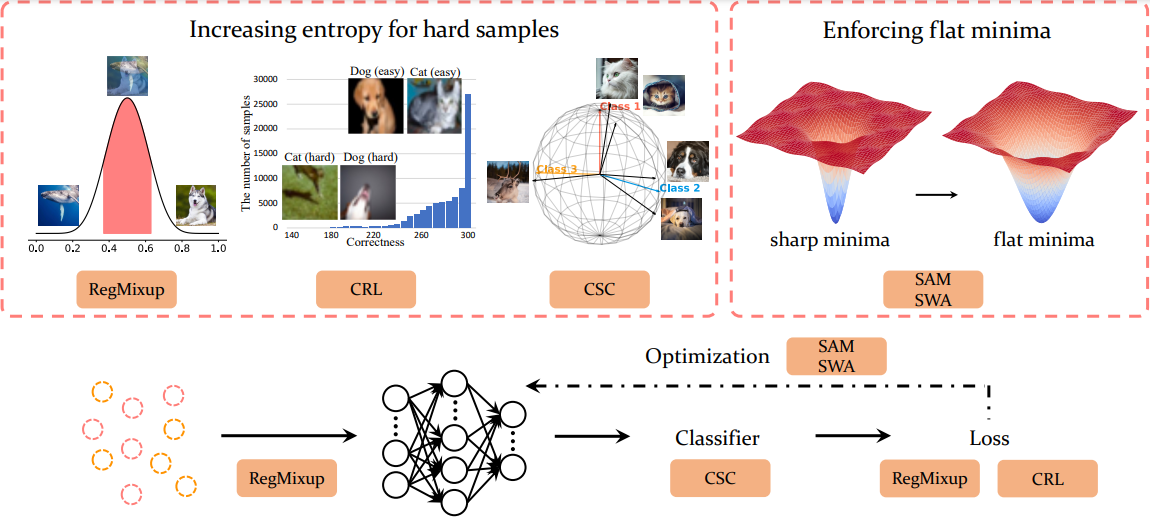
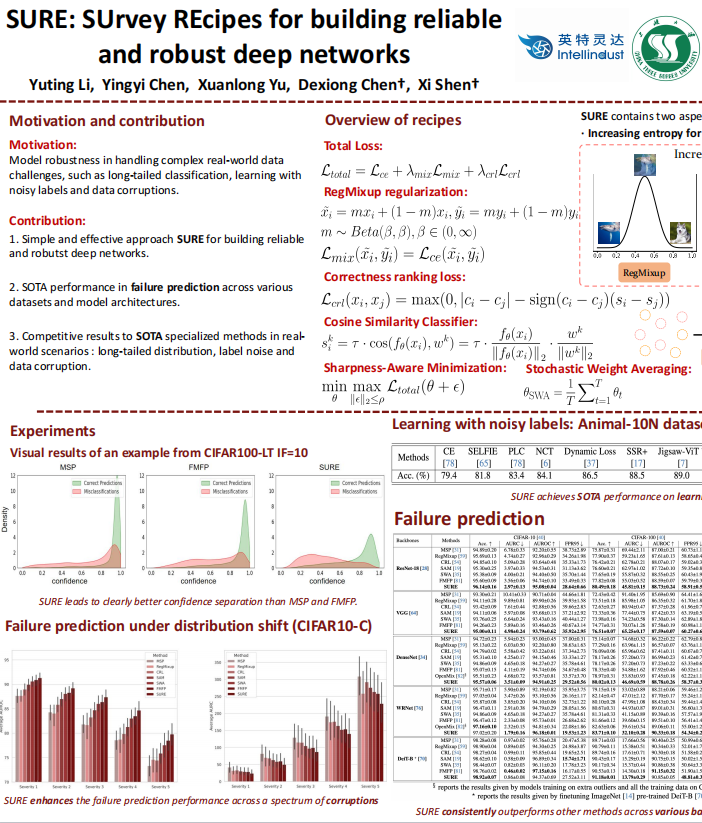
Our proposed approach SURE contains two aspects: increasing entropy for hard samples and enforcing flat minima during optimization. We incorporate RegMixup loss and correctness ranking loss (CRL) as our loss function and employ cosine similarity classifier (CSC) as our classifier to increase entropy for hard samples. As in optimization, we leverage Sharpness-Aware Minimization (SAM) and Stochastic Weight Averaging (SWA) to find flat minima.
Please refer to our paper for more experiments.


@inproceedings{li2024sure,
title={SURE: SUrvey REcipes for building reliable and robust deep networks},
author={Li, Yuting and Chen, Yingyi and Yu, Xuanlong and Chen, Dexiong and Shen, Xi},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
@article{Li2024sureood,
author={Li, Yang and Sha, Youyang and Wu, Shengliang and Li, Yuting and Yu, Xuanlong and Huang, Shihua and Cun, Xiaodong and Chen,Yingyi and Chen, Dexiong and Shen, Xi},
title={SURE-OOD: Detecting OOD samples with SURE},
month={September},
year={2024}
}
We thank Caizhi Zhu, Yuming Du and Yinqiang Zheng for inspiring discussions and valuable feedback.
© This webpage was in part inspired from this template.